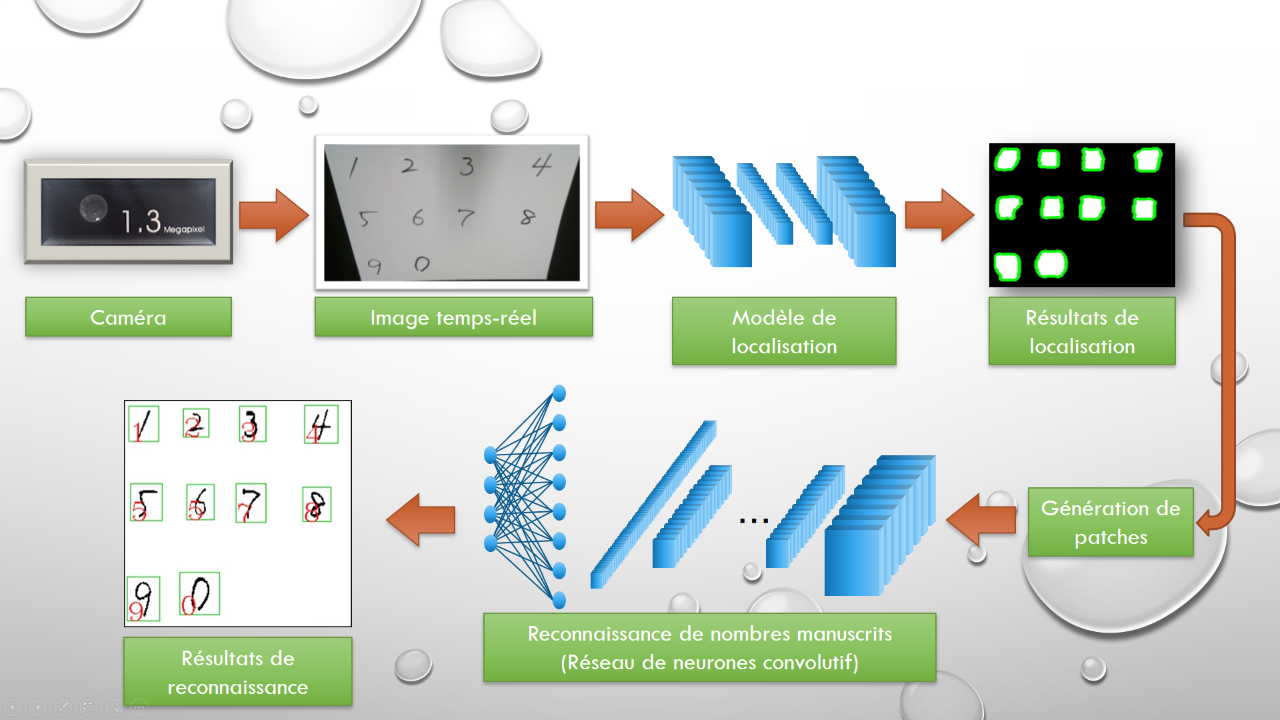
Lors du design des deux modèles, notre but principal était de créer la plus petite architecture possible tout en ayant une bonne précision de prédiction. Bien que la précision de notre modèle de reconnaissance ne soit pas la meilleure (la meilleure précision à notre connaissance est supérieure a 99.89%), nous avons réussi à créer un modèle ne comportant que 50,000 paramètres, ce qui le rend suffisamment compact pour être exécuté sur un ordinateur tel que le Raspberry Pi. Le modèle de localisation quant à lui se compose de 180,000 paramètres.
Le modèle de reconnaissance de nombres est un réseau de neurones convolutif standard utilisée pour une tâche de classification des nombres et a une précision de validation de 98.7%.
Le modèle de localisation est composé de couches de convolution suivies par des couches de convolutions/sur-échantillonnage dans le but de produire une prédiction sur chaque pixel de l’image. A partir de cette prédiction le système génère des patches à partir de l’image initiale et ceux-ci sont ensuite analysés un par un par le modèle de reconnaissance. Le modèle de localisation atteint une précision de validation supérieure à 97%.
Une des propriétés les plus intéressantes de ce système est selon nous dans la capacité du modèle de localisation d’effectuer une prédiction sur chacun des pixels. Ce type de procédure grâce a un réseau de neurones convolutif est une méthode qui peut être utilisée dans beaucoup d’applications de traitement d’images lié à la robotique. Par exemple, dans nos recherches sur la prédiction de profondeur à partir d’une image, cette technique est essentielle.
Une autre propriété intéressante de ce système se trouve dans l’équilibre existant entre la taille des modèles et leurs précisions de prédiction. Comme ces modèles sont relativement de tailles réduites, ils ne demandent pas beaucoup d’utilisation en mémoire et peuvent donc être exécutés sur des ordinateurs comme le Raspberry Pi.



")